Introduction
Reinforcement Learning has seen tremendous progress in interactive environments over the past few years, and the main proponents are Deep Learning and ever-advancing computational resources. However, RL has not yet totally achieved success in real-life environments. Imitation Learning still seems to be the most popular choice for this category. There is an additional problem: Can we generalize the task on out of distribution data. In this article, we study Imitation Learning in one of the robotic tasks and how generalization can be achieved. Furthermore, we talk about the persistent issue of sample inefficiency in RL related problems and how it can be mitigated.
Background and Prior Work
Imitation Learning can be broadly divided into 3 categories:
- Behavior Cloning
- Direct Policy Learning
- Inverse Reinforcement Learning
This article focuses on Behavior Cloning as they are the most simple and effective methods being used in robotic tasks.
Behavior Cloning
Behavior Cloning is a form of supervised learning, with the data or demonstrations being the trajectories of the interactions between the agent and the environment. An application of this has been self-driving cars (Bojarski et al. (2016)). Here, we assume the given demonstrations are perfect and hence, the agent is called Expert
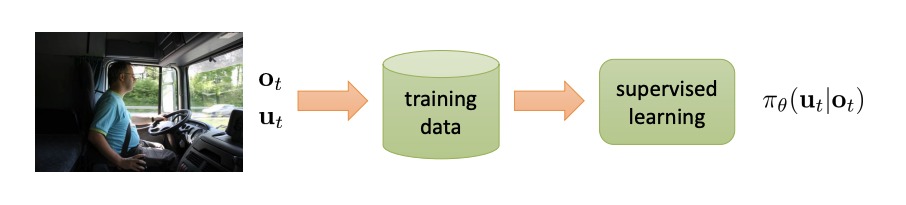

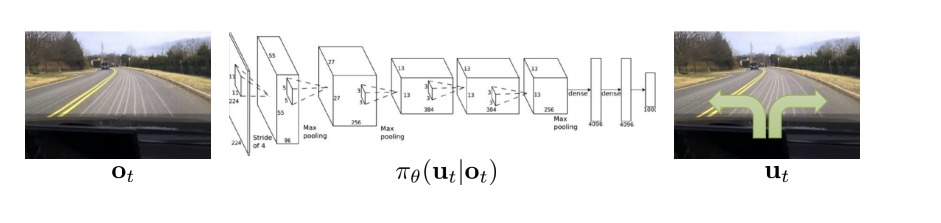
Self Supervised Learning
Given the availability of unlabeled data in high proportions, there has been an emphasis on utilizing the unlabeled data. This gave rise to the much known Self-Supervised Learning and are used in learning representations (Weng (2019)).
The idea behind Self-Supervised learning is to create some auxiliary pretext task for the model such that the model can learn the underlying structure of the image itself while solving the task. Here, we do not care about the model’s performance on the given tasks but only about the immediate image representations. Some examples of pretext tasks can be: predicting the rotation of an image, predicting the relation between different patches in an image, colorisation of an image etc.
A general objective a self-supervised model is to have: \[f_{\theta}(I)= f_{\theta}(augmentation(I))\]
A generic training pipeline for the Self-Supervised learning method is: where dash represent dash
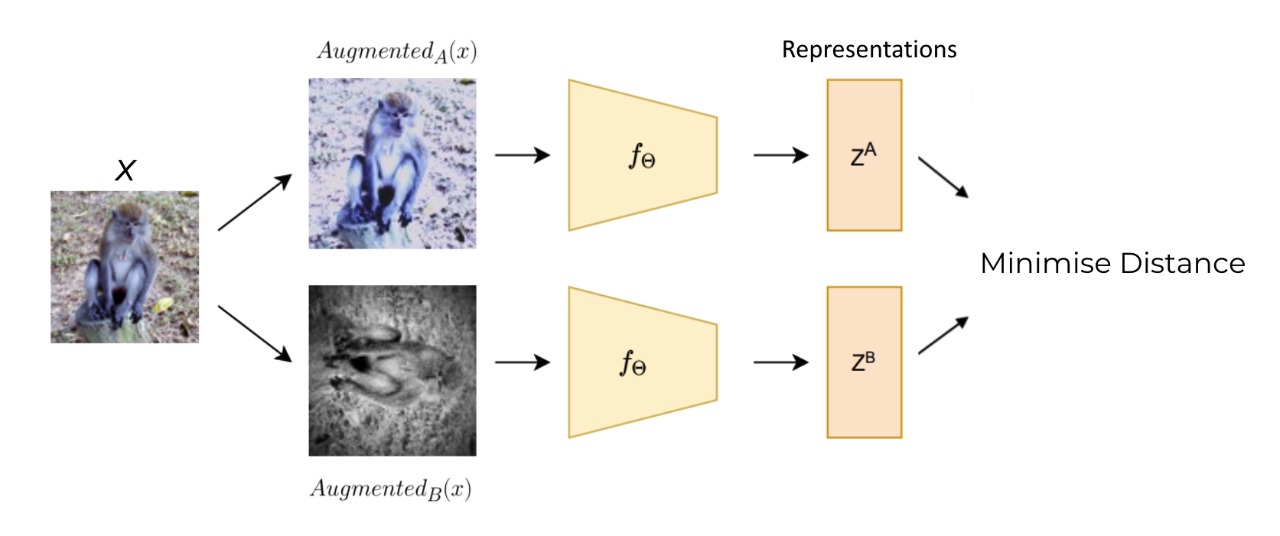
Many current state of the art SSL networks (SimCLR(Chen et al. 2020) and MoCo(He et al. 2020)) use Contrastive learning, which requires large negative samples to learn good representations. Unlike these methods, BYOL(Grill et al. 2020) achieves the state of the art performance without using negative samples and uses way less computation.We will be using BYOL for this project.
Non Parametric Control
Non-parametric models do not define data distribution in terms of a finite set of parameters. Instead, they make a prediction based on previously observed data. One of the most famous algorithms in a non-parametric model is K-NNs ( K Nearest Neighbor).
K-NNs assign labels to new data points by aggregating K nearest samples. They are easy to implement, requires no training time and are faster on small datasets.

Previous works like (Mansimov and Cho 2018) have shown that nearest neighbor methods are very successful in low dimensional control tasks.
Approach
Behavior Cloning is a good method when you can’t interact with the environment or there’s no have access to the expert later on while training. But they have their limitations (Codevilla et al. 2019):
- They don’t generalize well and perform poorly on out-of-distribution data.
- They are heavily biased towards the dataset provided.
- They require lots of data to train and perform with good accuracy.
As stated, generalization and sample efficiency are some of the key areas in RL research. We are going to discuss more about Self-Supervised Learning and how they can be combined with non-parametric methods to outperform behavior cloning as shown in Pari et al. (2021).
Generalization
RL has focused predominantly on the states to solve the problem. These can work fine in simulated environments as they have defined states if framed correctly but that is not the case in real world. States are too difficult to be estimated in the real world and observations are used instead (Young et al. (2020)). Observations can be in the form of images, videos, signals, etc. Image-based RL becomes key here and self-supervised learning helps us to make the best use of the observations. Some of the most recent popular methods in SSL are:
- BYOL (Bootstrap Your Own Latent) (Grill et al. (2020))
- SimCLR (Simple Framework for Contrastive Learning of Visual Representations) (Chen et al. (2020))
- VICReg (Variance-Invariance-Covariance-Regularization for Self-Supervised Learning) (Bardes, Ponce, and LeCun (2021))
Sample Efficiency
As said, there’s one more drawback with Behavior Cloning which is the need for huge data. Neural Networks are known to have this problem. Or, they are very hard to train and one of the reasons is the instability in the parameter updates (Goodfellow, Bengio, and Courville (2016)). One alternative to this can be non-parametric methods like K-Nearest Neighbors.
Task

Reach Task on the Stretch Robot
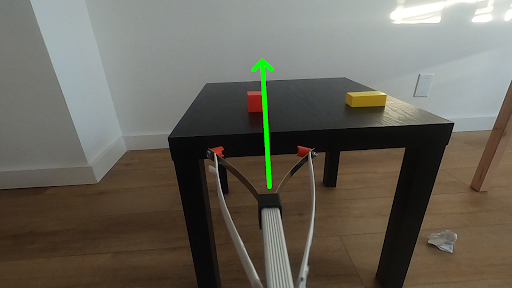
We follow the exact same approach as VINN (Visual Imitation through Nearest Neighbor). The main task there was door opening and the method is shown to be quite effective. We extend this to a new task, the reach task where there are two objects, one red and one yellow. The robot has to reach for the red object.

The bot has to reach the red block
Training Prcocedure
Inspired by Pari et al. (2021), our training pipeline is divided in 2 stages:
- Learning good representations through SSL
- Querying encoded representation against expert trajectories using K-NN.
Representation Learning
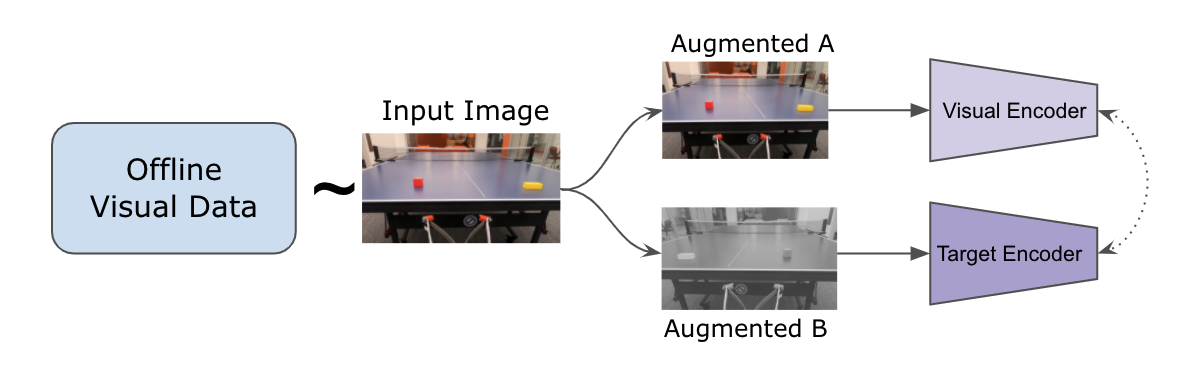
The individual images are extracted from expert trajectories and are annotated with actions which will be explained in the later sections. These annotated images are passed to an SSL model to learn feature representations. These representations are used instead of the state embedding as generally used in RL. These representations are later used in VINN or Behavior Cloning.
Qeurying through K-Nearest Neighbors
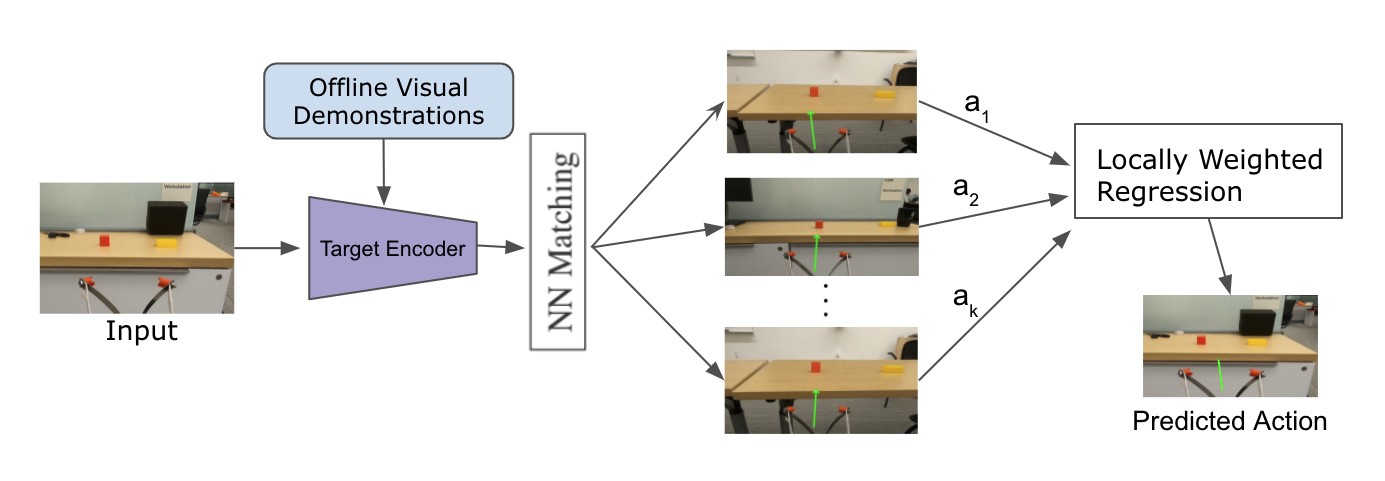
During evaluation, given an input we take the encoded offline demonstrations and search for frames with similar features. We rank them according to their similarity and choose corresponding actions from best K feature frames. For our task in this project, we have selected the value of K=5 as we get best results for that value of k.
The final action is a weighted average of the best K feature-action pair. The weight is decided by the SoftMin of the features distance to the query image. The formula can be given as:
\[\hat{a}= \frac{\sum^k_{i=1} \exp(-||e_q-e_i||_2).a_i}{\sum^k_{i=1}\exp(-||e_q-e_i||_2)}\] Where \(e_q\) is the query feature embedding, \(e_i\) is the \(i_{th}\) sample’s feature embedding and \(a_i\) is the action associated with that \(i_{th}\) sample.
Setup
The main setup has been done at New York University CILVR Lab. Instruments used here GoPro, reacher-grabber, hello stretch robot.
Demonstrations
Using the reacher-grabber stick and GoPro camera mounted on the stick, we have collected a total of 181 demonstrations. The videos capture a stick proceeding towards the red block with different placement of the blocks in various environments.




 A total of 181 demonstrations are collected which are split into training of 145 and validation of 36
A total of 181 demonstrations are collected which are split into training of 145 and validation of 36
Action Estimation
After collecting demonstrations, image frames are extracted using openSfM software which are then fed to an SSL model to learn image representations. OpenSfM also generates the translation, rotation vectors or change in movements. Using these vectors, actions are calculated with which we get the representation-action pairs or state-action pairs.
Robot
The robot we have used is Hello Robot - Stretch. The models are deployed on a server and we use ROS for communication between the robot and the server. We use PyKDL for robot to do the inverse kinematics and perform actions calculated/predicted by the models.
Observations and Results
Robot Experiments
We have used 3 models:
- VINN (BYOL): BYOL is trained using a ResNet-50 (pretrained on ImageNet) on 100 epochs with batch size of 168. VINN applies K-NN on the feature vectors produced from the BYOL model with \(k = 5\) and takes the weighted average of the actions from the nearest neighbors.
- BC (Representations): BC uses the feature vectors produced from the BYOL model and trains a translation model. This is trained on 8000 epochs with batch size of 256.
- BC (End-to-End): BC is trained using a pretrained ResNet-50 along with the translation model on 100 epochs. ResNet-50 weights are also updated in the process.
We have performed tests on 2 environments, 8 runs with each model:
Environments
- Environment-1: This environment is similar to the ones in the training dataset. The image frames will be similar and the models are expected to perform better than that in environment-2.

- Environment-2: This environment is completely new because of the background and the black table cloth. This can be considered as an out-of-distribution data.

In total, these constitute 48 runs in total. Results are shown below:
ENVIRONMENT 1
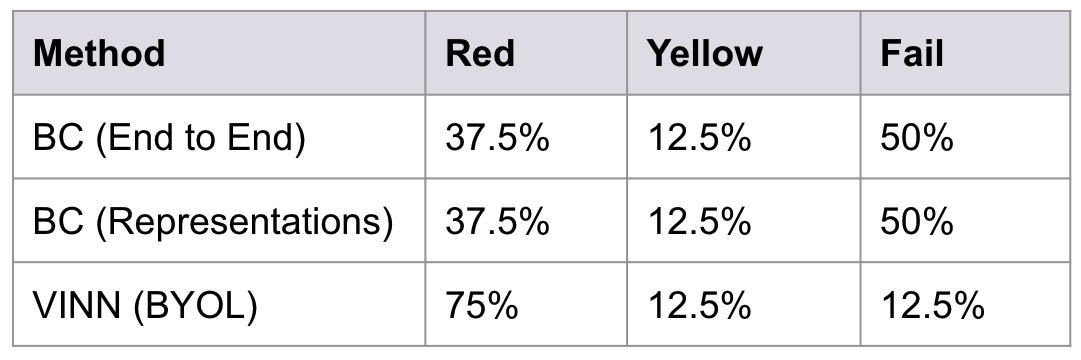
Some pass and failure scenarios for the 3 algorithms on Environment 1:
|
VINN |
BC (Representations) |
BC (End to End) |
|
| Scenario 1: |

PASS |

FAIL |

FAIL |
| Scenario 2: |

FAIL |

FAIL |

PASS |
ENVIRONMENT 2
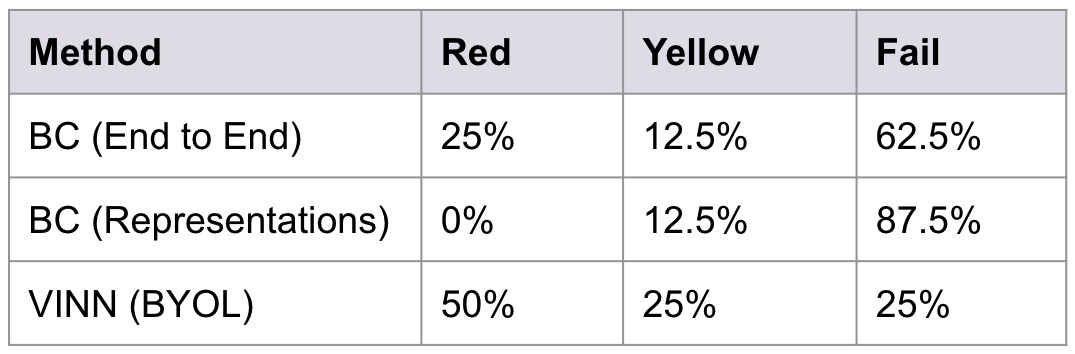
Some pass and failure scenarios for the 3 algorithms on Environment 2:
|
VINN |
BC (Representations) |
BC (End to End) |
|
| Scenario 1: |

PASS |

FAIL |

FAIL |
| Scenario 2: |

PASS |

FAIL |

PASS |
As we can see, VINN outperforms both BC (Representations) and BC (End to End) with some margin in the first environment. In the second environment, BC methods fail because of the test data being out-of-distribution data. VINN still manages to get better results in this case.
On the other hand, if we observe BC(End-to-End) we see that it predicts the same action in all the environments. In a funny way, two out of the 4 scenarios just work out by themselves due to the block position. This shows that, if given limited data BC will be highly biased on the kind of data it is trained on. Whereas, in the case of VINN, it can still learn to take right actions.
Offline Evaluation
This section covers the offline evaluation.
Metric: We have used a simple MSE loss for the evaluation.
We compared MSE loss performance by various models:
- BC (End to End): BC trained end to end as described previously.
- BC (Representations): BC trained using representations from BYOL as described previously.
- VINN-BYOL (Pretrained + Reach): BYOL model trained on reach data using a pretrained ResNet-50 as described previously.
- VINN-BYOL (No pretrained + Reach): BYOL model trained on reach data using a ResNet-50 with no pretrained weights.
- VINN-SimCLR (Pretrained + Reach): VINN uses SimCLR model that’s trained on reach data using a pretrained ResNet-50.
- VINN-VICReg (Pretrained + Reach): VINN uses SimCLR model that’s trained on reach data using a pretrained ResNet-50.
| Method | MSE Loss (\(\times 10^{-1}\)) |
|---|---|
| BC (End to End) | \(\boldsymbol{1.6 \pm 0.06}\) |
| BC (Representations) | \(1.9 \pm 0.09\) |
| VINN-BYOL (Pretrained + Reach) | \(1.8\) |
| VINN-BYOL (No pretrained + Reach) | \(1.9\) |
| VINN-SimCLR (Pretrained + Reach) | \(1.9\) |
| VINN-VICReg (Pretrained + Reach) | \(1.8\) |
Additionally, we have checked how the models perform with different dataset lengths.
Clearly, BC (End to End) has the best loss among these methods and the next best is VINN (BYOL).
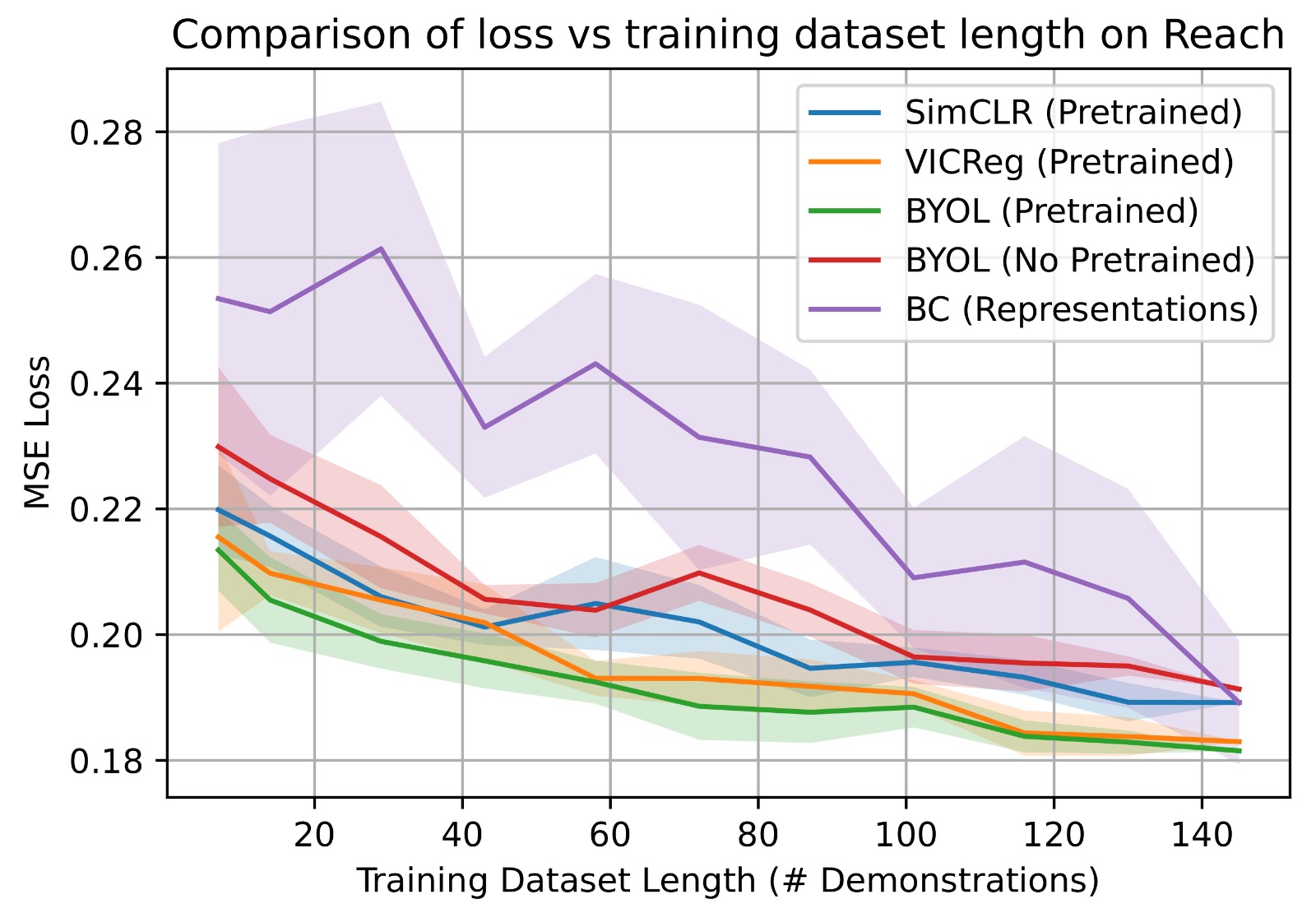
It is evident that with fewer samples of data, VINN manages to achieve similar MSE loss compared to BC. This demonstrates the importance of K-NN as they help in achieving a credible performance with not much requirement of data.
K-NN Visualization

These are some of the examples where VINN produces correct nearest neighbors for the input image observed by the robot during the experiments. We can see that the resulting action is the weighted average of the actions of the nearest neighbors.
Limitations and Future Work
Limitations
We have seen the potential of self-supervised learning for generalization. But there are still some limitations here because of poor representation learning due to which nearest neighbors aren’t calculated properly and the algorithm struggles to perform the task. One solution to this is to do incremental self-supervised learning so that the algorithm becomes robust as and as it interacts with newer environments.
Future Work
This framework has the scope to be extended to generalization on tasks as well. With better representation learning on multiple tasks, this simple algorithm can be powerful for multi-tasking problems.
Acknowledgements
We would like to thank Prof. Lerrel Pinto for providing us such a great opportunity and platform to work on this problem. We would like to thank Jyothish Pari for providing us the framework related to this project. We also thank Mahi Shafiullah, Sridhar Pandian in helping and providing all the support regarding the project.